Publications
By clicking on PDF, you may be directed to my research notes on the respective work. If you wish to see the actual paper, please access the HTML which directs to the arXiv-generated page, where you can find the PDF of the paper.
2025
- Under-Review
 Age of Information Minimization in Goal-Oriented Communication with Processing and Cost of Actuation Error ConstraintsRishabh S. Pomaje, Jayanth S., Rajshekhar V. Bhat, and 1 more author2025
Age of Information Minimization in Goal-Oriented Communication with Processing and Cost of Actuation Error ConstraintsRishabh S. Pomaje, Jayanth S., Rajshekhar V. Bhat, and 1 more author2025We study a goal-oriented communication system in which a source monitors an environment that evolves as a discrete-time, two-state Markov chain. At each time slot, a controller decides whether to sample the environment and if so whether to transmit a raw or processed sample, to the controller. Processing improves transmission reliability over an unreliable wireless channel, but incurs an additional cost. The objective is to minimize the long-term average age of information (AoI), subject to constraints on the costs incurred at the source and the cost of actuation error (CAE), a semantic metric that assigns different penalties to different actuation errors. Although reducing AoI can potentially help reduce CAE, optimizing AoI alone is insufficient, as it overlooks the evolution of the underlying process. For instance, faster source dynamics lead to higher CAE for the same average AoI, and different AoI trajectories can result in markedly different CAE under identical average AoI. To address this, we propose a stationary randomized policy that achieves an average AoI within a bounded multiplicative factor of the optimal among all feasible policies. Extensive numerical experiments are conducted to characterize system behavior under a range of parameters. These results offer insights into the feasibility of the optimization problem, the structure of near-optimal actions, and the fundamental trade-offs between AoI, CAE, and the costs involved.
@misc{pomaje2025ageinformationminimizationgoaloriented, title = {Age of Information Minimization in Goal-Oriented Communication with Processing and Cost of Actuation Error Constraints}, author = {Pomaje, Rishabh S. and S., Jayanth and Bhat, Rajshekhar V. and Pappas, Nikolaos}, year = {2025}, eprint = {2508.07865}, archiveprefix = {arXiv}, primaryclass = {cs.IT}, url = {https://arxiv.org/abs/2508.07865}, }
2024
- Pre-Print
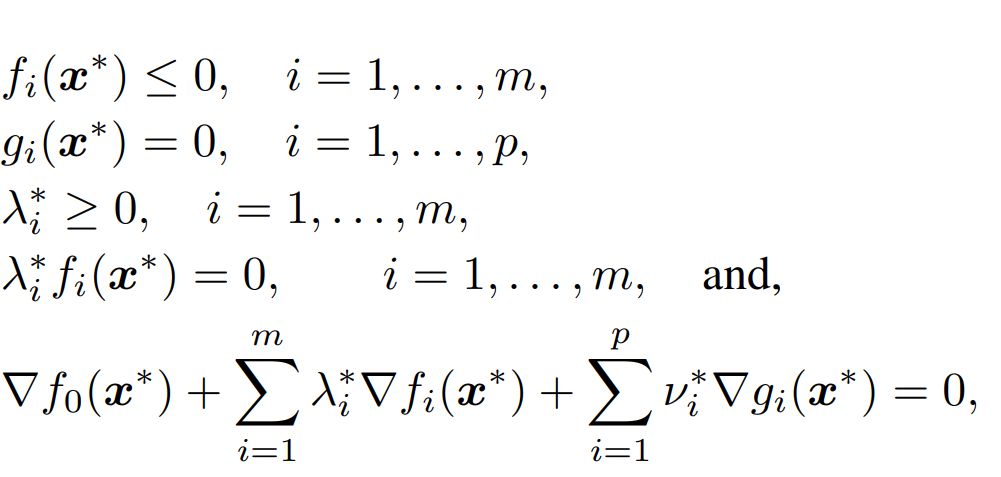 Karush-Kuhn-Tucker Condition-Trained Neural Networks (KKT Nets)Shreya Arvind, Rishabh Pomaje, and Rajshekhar V Bhat2024
Karush-Kuhn-Tucker Condition-Trained Neural Networks (KKT Nets)Shreya Arvind, Rishabh Pomaje, and Rajshekhar V Bhat2024This paper presents a novel approach to solving convex optimization problems by leveraging the fact that, under certain regularity conditions, any set of primal or dual variables satisfying the Karush-Kuhn-Tucker (KKT) conditions is necessary and sufficient for optimality. Similar to Theory-Trained Neural Networks (TTNNs), the parameters of the convex optimization problem are input to the neural network, and the expected outputs are the optimal primal and dual variables. A choice for the loss function in this case is a loss, which we refer to as the KKT Loss, that measures how well the network’s outputs satisfy the KKT conditions. We demonstrate the effectiveness of this approach using a linear program as an example. For this problem, we observe that minimizing the KKT Loss alone outperforms training the network with a weighted sum of the KKT Loss and a Data Loss (the mean-squared error between the ground truth optimal solutions and the network’s output). Moreover, minimizing only the Data Loss yields inferior results compared to those obtained by minimizing the KKT Loss. While the approach is promising, the obtained primal and dual solutions are not sufficiently close to the ground truth optimal solutions. In the future, we aim to develop improved models to obtain solutions closer to the ground truth and extend the approach to other problem classes.
@misc{arvind2024karushkuhntuckerconditiontrainedneuralnetworks, title = {Karush-Kuhn-Tucker Condition-Trained Neural Networks (KKT Nets)}, author = {Arvind, Shreya and Pomaje, Rishabh and Bhat, Rajshekhar V}, year = {2024}, eprint = {2410.15973}, archiveprefix = {arXiv}, primaryclass = {cs.LG}, url = {https://arxiv.org/abs/2410.15973}, } - Pre-Print
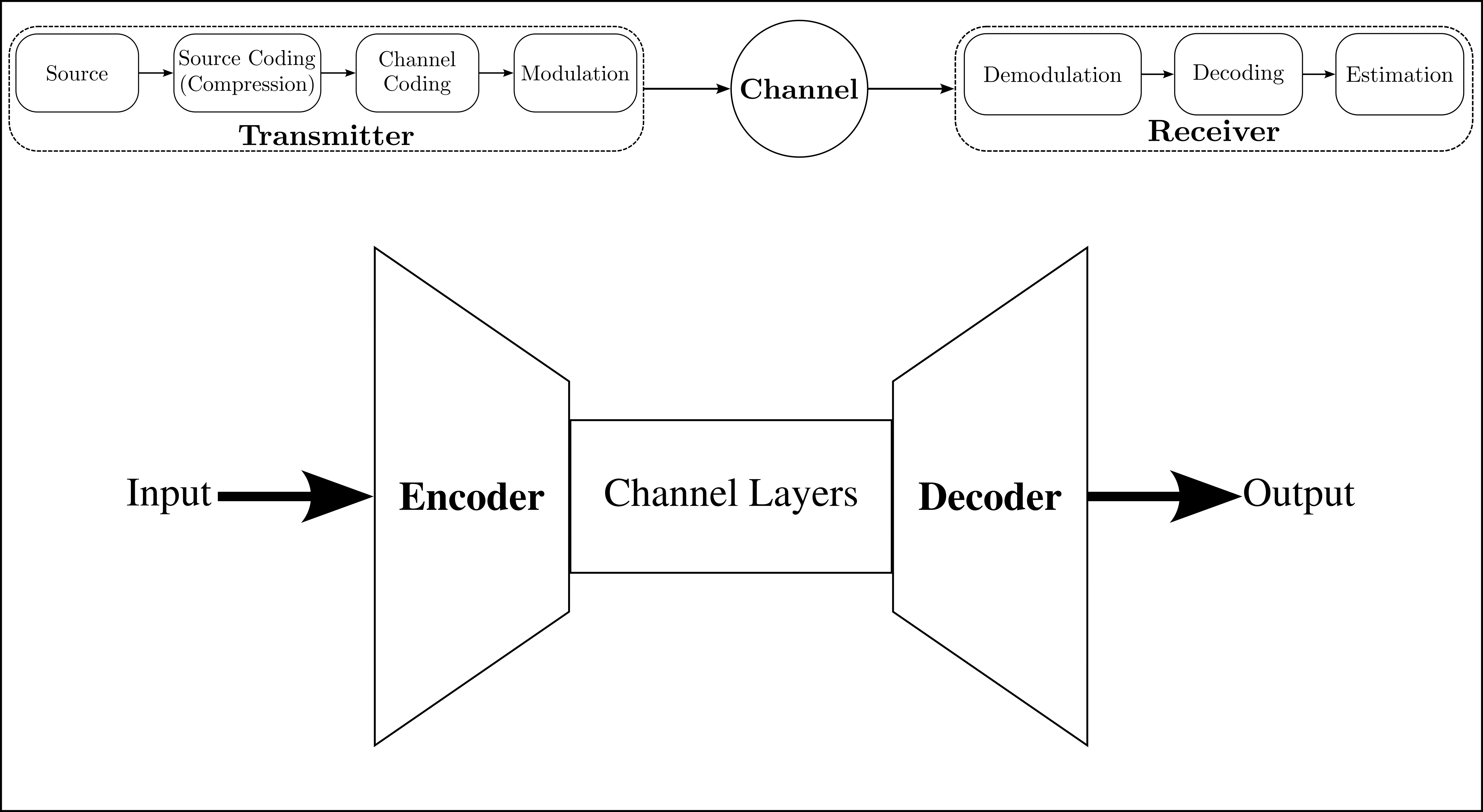 Learning Short Codes for Fading Channels with No or Receiver-Only Channel State InformationRishabh Sharad Pomaje and Rajshekhar V Bhat2024
Learning Short Codes for Fading Channels with No or Receiver-Only Channel State InformationRishabh Sharad Pomaje and Rajshekhar V Bhat2024In next-generation wireless networks, low latency often necessitates short-length codewords that either do not use channel state information (CSI) or rely solely on CSI at the receiver (CSIR). Gaussian codes that achieve capacity for AWGN channels may be unsuitable for these no-CSI and CSIR-only cases. In this work, we design short-length codewords for these cases using an autoencoder architecture. From the designed codes, we observe the following: In the no-CSI case, the learned codes are mutually orthogonal when the distribution of the real and imaginary parts of the fading random variable has support over the entire real line. However, when the support is limited to the non-negative real line, the codes are not mutually orthogonal. For the CSIR-only case, deep learning-based codes designed for AWGN channels perform worse in fading channels with optimal coherent detection compared to codes specifically designed for fading channels with CSIR, where the autoencoder jointly learns encoding, coherent combining, and decoding. In both no-CSI and CSIR-only cases, the codes perform at least as well as or better than classical codes of the same block length.
@misc{pomaje2024learningshortcodesfading, title = {Learning Short Codes for Fading Channels with No or Receiver-Only Channel State Information}, author = {Pomaje, Rishabh Sharad and Bhat, Rajshekhar V}, year = {2024}, eprint = {2409.08581}, archiveprefix = {arXiv}, primaryclass = {cs.IT}, url = {https://arxiv.org/abs/2409.08581}, }